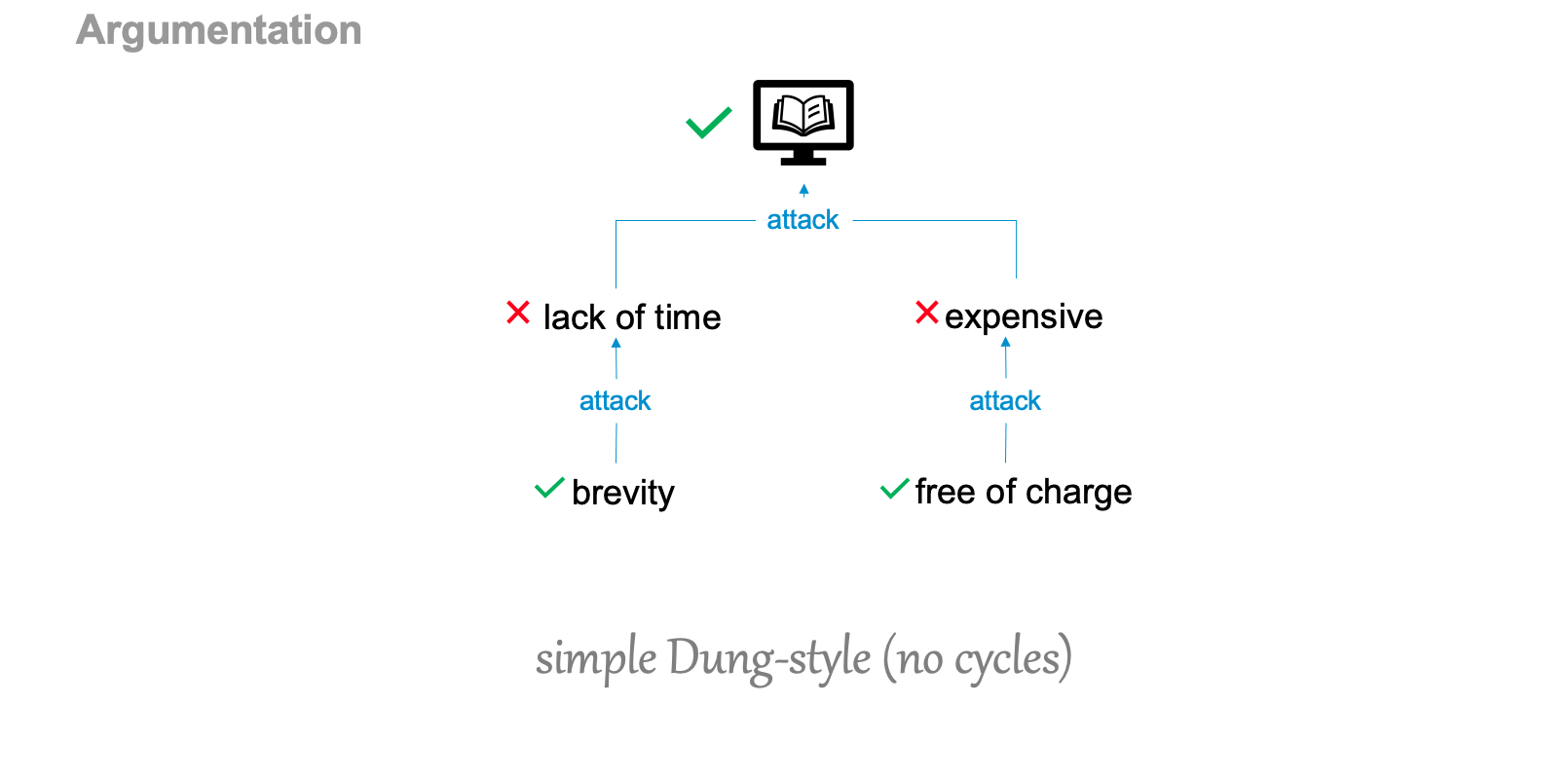
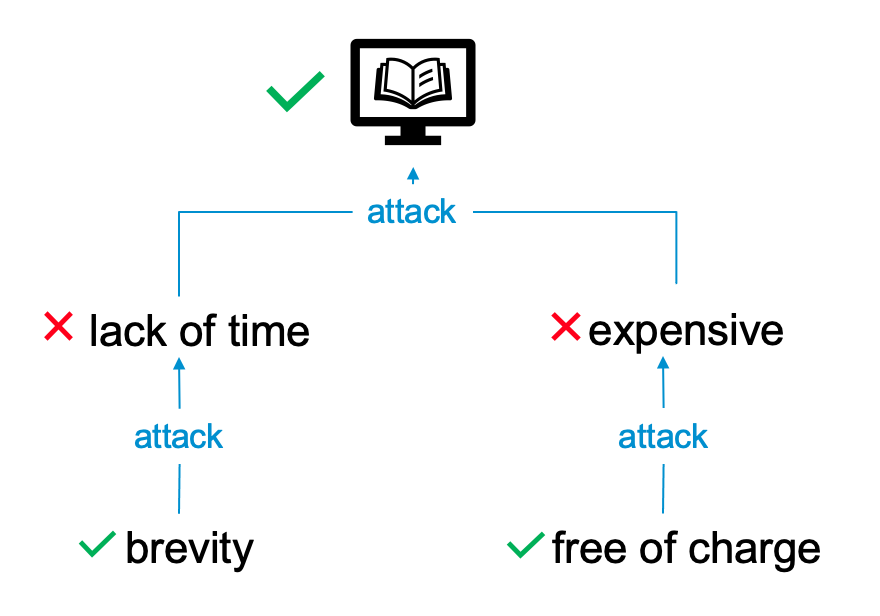
What could possibly go wrong in the chain of suppliers? The risk could be caused by unexpected:
- unavailability of suppliers for:
- own internal reasons
- suppliers’ suppliers availability risk
- issues in the distribution
- rising costs due to:
- distribution chain
- raw material
- lowering of competitive alternatives in the market
- geo-political issues
- wars
- international sanctions
- natural adversities
This short dissertation aims to analyze the architecture of a potential cognitive system designed to alleviate these supplier-related problems.
What is a cognitive system? Cognitive systems, in essence, are intelligent agents capable of learning, reasoning, adapting to new environments, and leveraging past experiences to continuously improve. The key advantage? They can deliver high-value functionalities with minimal human intervention.
What is a cognitive system architecture? In the realm of software, designing an architecture means to trace the invariant aspects and components that meet expected requirements and functionalities. Two well-established cognitive architectures, SOAR and ACT-R, have been under development for decades and will be the foundation for this exploration.
System goals
As it clearly appears, nearly all elements involved in the corporate’s values chain may be impacted by supply management, the procurement will influence all the other elements even top business priorities. This is why a system that fulfill the functionalities proposed here will be important for almost all companies and surely for manufacturing ones.
The goals of the system is to help analysts to mitigate risks related to the supply network and provide more suitable alternatives to lower those risks.
How would the system actually help?
The system is intended to provide probabilistic estimations on a variety of natural language queries. It will elaborate how much target forecasts diverges from current estimations according to real-time analysis. The purpose is to raise issues that may undermine the predicted costs for the business, and to raise awareness on auspicable chances to re-organize the supply chain.
Not limited to that, the system should provide estimations in the current state of affairs and also in hypothetical situations artificially setup by tweaking initial conditions.
If you are think of a simulation engine, this is exactly what I mean with that.
The tool should elaborate possible consequences and, in cascade (recursively), analyze further outcomes from them. Analysts may advance simulations on particular conditions, specifying by natural language propositions, some constraints such as:
What will be the impact on the deliveries for supplier $XYZ$ on a increase of +30% of the cargo shipping costs?
Types of simulation may involve complex aspect of related to change in demand from their customer side as in how the supply provisioning will be affect on % increase product X and % decrease of product Y?
Considering a particular simulation on changes in the manufacturing process, queries may be of interest for industrial managers where processes changes will drive to different procurement due to innovations and optimizations:
What are the costs estimations for our smartphones if we replace plastic cover with alloy masked covers?
Data & system heterogeneity
For performing the wished functionalities the system should elaborate a massive quantity of facts, analyze them, evaluate their impact on direct suppliers and their upstream suppliers. The generality of the term “analysis” hides numerous computational intensive tasks for capturing regularities in the data, so it would much easier to replicate past decisions once they have been learned1. By impact it is intended of events that have direct effect on carrying goods around the world and their production, and also events that may be indicative of changes in mood regarding a particular technology or company or geopolitical area. Rumors usually are seriously taken into account by decision makers, but at the same time they might lead often to false positives as well.
Data awareness2 is just one of the ingredients we need for this recipe. Business processes are not designed by tons of terabyte of data, rather they are intentionally crafted by experts and the decisions on setting up how things should be made up for their business are derived to general ways to conduct a specific process (therefore generalizable in templates) but they could also be unique for that business. We may generalize process modelling as:
- hierarchical. Because processes are generalizable into typical (following the prototype theory3) cases
- non-monotonic. Peculiarities are the norm, and every process may differ from the general one.
- compositional. Process models are associative and composable into macro-processes.
Data heterogeneity
Differently from expert input - used for defining how actual industrial and business processes work - all the other type of input is inherently unstructured and noisy. The evaluated architectures propose an approach that tackles the challenge of reconciling symbolic and connectionist representations for robust AI. This heterogeneity allows for diverse data formats and enables the integration of symbolic (cognitivist, based on symbolic logic) and emerging (connectionist, based on neural networks) approaches within a single system by leveraging existing architectures such as SOAR and ACT-R.
Cognitive features
Despite the high degree of uncertainty, ambiguity, and common sense – qualities even humans struggle with – automatic systems must grapple with these challenges. These processes require a set of cognitive skills. But what exactly is cognition within the realm of automatic systems? In the realm of automatic systems, Vernon4 has several depictions of what cognition might be:
Cognition is the process by which an autonomous system perceives its environment, learns from experience, anticipates the outcome of events, acts to pursue goals, and adapts to changing circumstances.
I would point to this more intriguing definition extracted again from his book “Artificial Cognitive Systems”:
Cognition is the means by which the system compensate for the immediate ‘here and now’ nature of perception, allowing it to anticipate events that occur over longer timescales and prepare for interaction that may be necessary for the future.
Cognition is the Swiss-knife of intelligent animals that strive to maximize their surviving chances in the environment where they live. Adapting to uncertain circumstances is not an exception, therefore the ability to self-improving is one among first principles:
Cognition is the result of a developmental process through which the system becomes progressively more skilled and acquires the ability to understand. Anticipation and sense-making are the direct result of the developmental process.
Let’s summarize the reasons why the system should pursue the virtues of cognition:
Inferences
The ability to make inferences about events that might impact a business process. Obviously the most important feature. Those events include the actions a company should ruled out according to the system recommendations. To make such inferences, the system should look back into the past and combine that experience with given processes definitions
Feedback-loop
To notice when performance are degrading, identify the reason of such low outcome and take corrective evaluation. The system should engage a feedback loop in order to minimize estimation errors. This feedback could be negative or positive according to the predictions. The feedback could be seen automatically from historic data (supervised learning) but also from experts that can help to draw a causality network of believes used by the system to infer unseen situations.
Autonomy
The automatic agent should actively trigger alarms concerning its goals and inform about risks and/or actions to take. For that, the system should not only ingest/parse/elaborate the information input, but autonomously search for those sources in order to improve its decision-making capability.
Continuous learning
If we assume that cognitive architecture forms the basis for intelligent system in uncertain environments, it should incorporate a flexible approach toward learning and skills improvements.
While narrow ML system distinguish training from inference, and expert systems take the given knowledge as granted, a cognitive system should develop an understanding of the world by constructing theories that explain and predict events and behaviors.
Continuous learning adhere to the theory-theory view5 by which the agents don’t passively accumulate knowledge, but they actively construct and revise (by leveraging counter-factuals) continuously what understood. This reflects a pillar of cognitive system referred as development. It states the importance of self-improvement and it is achieved by self-modification, in this view not only the environment perturb the system, but the system perturb itself 6.
Simulations
The system should run simulations for predicting alarms might happen in the supply chain. A simulation occurs anytime there is change in the information, even though it does not affect the tree of suppliers. This is due to the cascading consequences events may cause to apparently unrelated entities.
Interaction with other agents
For making sense of the world, cognitive agents have to transform the knowledge acquired through senses into meaningful affordances with which they can achieve their goals. The appreciations of semantic concepts into meaningful concepts is obtained not only by the interconnection with other concepts, but also by interaction with other agents and exchanging those concepts for knowledge sharing. Vernon perfectly summarize that in:
the meaning of the knowledge that is shared is negotiated and agreed by consensus through interaction
Though the supply chain agent would certainly benefit of this skills, remaining dubious its applicability in business contexts. Intellectual properties that the system is intended to conceptualize are secret by definition, therefore the propensity of sharing information that may leak confidential data (business internal structures, process models of any kind) is approximately zero. Even non confidential data may be not shareable for the risk to advantage competing agents.
Overview of main cognitive architectures
Over decades of research, the field of cognitive systems have seen the rise of a multitude of different designs for what could be defined the artificial cognitive architecture. The two more articulated approaches that have been developed are the SOAR and the ACT-R architecture. The have been inspired by diametrical different motivations. The ACT-R is definitely inclined toward modelling and replicating human cognitive processes, while the former was driven by the ambition to supersede the functionalities of an intelligent cognitive system, whether or not inspired by existing biology.
It turns out that despite the differences, the two paradigms are not so far from each other, a grossly simplified similarity is here provided.
Comparison SOAR/ACT-R
In both architectures, persists the separation of declarative memory (the set of info that we may think consciously of them when we need) from procedural memory (enacted and automated skills, such as riding a bike). Both approaches are mostly based on symbolic representation though actions (or operators in SOAR) are evaluated against continuous ranges of utilities which is adopted as reward for reinforced learning.
While the concept borrowed from cognitive psychology about working memory is a pillar of both systems, it is implemented in different ways. In SOAR, working memory is a centralized space for imminent processing, in ACT-R it is a sparse swap space between modules and modules -> central processing. Being both goal oriented, the approach taken for decision making in SOAR differs and deserve a mention.
Whenever there are multiple operators to select, SOAR attempts to fine tune the raking in order to let just one operator (action to take) to emerge. It solve such impasse setting intermediate goals with the purpose of discriminate the best operator. Among the list of differences, I find it interesting the different learning consolidation between the two, surely due to the different foundational motivations. in ACT-R a rule is consolidated (stored and actionable in procedural memory) after a series of re-learning, in SOAR the consolidation is immediate after its production.
Cognitive system structure
Data input
For performing the expected analysis the system requires different type of information: process models and sparse factual data. The first define the processes that the system is intended to optimize for what supply management concerns. The second is the flow of information that might trigger cascading events that affect evaluations and alarms. The processes models are transcribed and supervised by experts but also derived by already existing representations such as BPM models, so it is both a manual and automatic process. The data flow, on the other hand, is completely automatic, and data source may be listed as:
- suppliers info:
- official financials reports. E.g.: quarterly CEO reports.
- news & rumors from social media/magazines.
- central banks communications. Interest rates might strongly affect costs of debts.
- inventory reports. Aggregated changes on company inventories can say something regarding raw material trend prices.
- Oil prices. Anything that might affect transportation cost.
- International political tensions. Clashes between countries/groups may result in chain disruptions.
- important local events like Olympiads or G7 meetings may alter the usual exchange of goods and the freedom of movement of people.
- natural disasters.
- historic records of all above for training purposes.
Summarizing the type of input I would list them into: - news text streams
- company and supplier models that describe business and internal processes.processes are described by symbolic means through some domain specific language such as BPM or other logical and temporal language. Such representation should be denotative and connotative for objects and processes 7
Architecture overview
What is architecture in the context of a cognitive system? Again, Vernon4 comes to rescue with:
…architecture has been borrowed by many other disciplines to serve as a catch-all term for the technical specification and design of any complex artifact. Just as with architecture in the built environment, system architecture addresses both the conceptual form and the utilitarian functional aspects of the system, focusing on inner cohesion and self-contained completeness.
The forms follow functions8 approach adopted for this project drag attention toward the SOAR architecture for a variety of reasons such as:
- It is adopted a completely functionalist approach. It’s irrelevant whether the set of cognitive processes are closer to the current state of knowledge on how human brain process information. While it is important to consider the implications an intelligent system might have for accomplishing its functions, it is not vital that they are adherent to the human mind.
- The knowledge the system may handle would be always incomplete, therefore chain of reasoning will always encounter impasses. Impasse will be the natural intermediate state of any evaluation since the semantic and the procedural knowledge would never be suited for all encountered fact consequences.
However, some ideas will be borrowed from ACT-R as well: - Production compilation. It is a learning task devoted to aggregate multiple rules for composing macro-functionalities. Rule re-usability is an optimization milestone for speed-up learning of complex production rules.
Modules
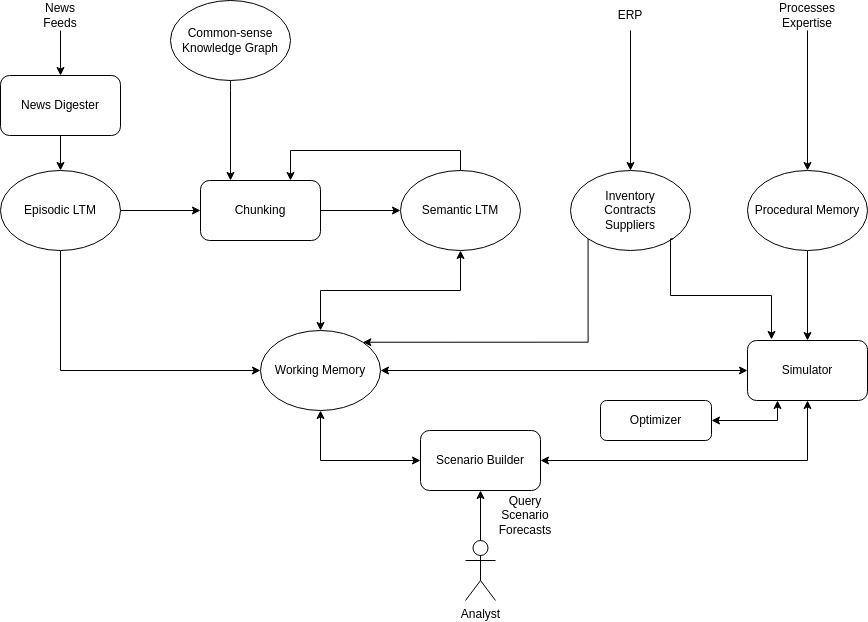
- News Digester. The module transform the incoming data from news feed (but also many other sources, see above description) into propositional statements according to first order logic. Those statements will be stored in triple-store databases, which constitutes the episodic long-term memory.
- Chunking. This module is inspired by the homonym component in SOAR. It is devoted to learn new behaviors/actions in certain conditions. Learning means creating new rules that can accomplish better estimations. Since the knowledge encoding is symbolic, chunking would comprise learning methods for discrete representations such as probabilistic inductive logic programming, that combines deterministic learning with probabilistic likelihood of the output propositions.
- Simulator. How the system is supposed to answer questions regarding forecasts in case of hypothetical events and conditions? This is what the simulator is entitled for. It run all existing rules all over all defined processes until a number of stable models are generated by the system. Those models represent a state might occurs in a determined time step, therefore they will be used on extracting the requested metric (delivery date, prices, etc..) in that particular case. Such models are probabilistic, that means they are associated with degree of uncertainty that is reflected to the requested metrics as well.
- Optimizer. Paired with the simulator, an optimization engine will act as a rational daemon for the chain of decisions a player involved in the business processes is supposed to behave. The simulation will involve game theoretical analysis because external agents’ decisions must be taken into account on evaluating requested metrics. For example, changing supplier might put the excluded one in the conditions to offer their products/services at discount cost to the competitors, initiating a cascading chain or eroded margin that are not welcome by shareholders. The optimizer would trigger that alarm during the simulation, informing the analysts of possible earning risks.
- Scenario builder. This is the user interface module, for gathering constraints and given events for running simulations. The module will allow to retrieve specific evaluation metrics for the current state of events as well.
Above the list comprehend computational modules intended to elaborate information which is stored and represented in the storage modules described below: - Episodic long-term memory. This database holds all propositions that regards events and facts. The information is saved in triple-store databases.
- Semantic long-term memory. In here, the information representation is different from the episodic memory. A probabilistic likelihood is associated to proposition rules, which might have particular additional characteristics such as: symmetry and transitivity. This information module is recursive in the way that it is possible to specify recursive relations that have the advantage to be very declarative and concise in their definition. Of course, the database should be capable to deal with recursive structures and implement particular policies for optimizing the computation of (virtually infinite) depth of computation.
- Working memory. Among the storage modules this is the most active, in the sense that it is supposed to cache the information that is temporary generated but at the same time, WM should anticipate the demand of information from long (and slow) term memories. Therefore, particular expedients should be employed to optimizing database lookups.
- Procedural memory. This is the place for storing internal/external production and business processes models and they are provided by knowledgeable operators. This is the core of the expert system side of the entire system, where the human experience is encoded for being processed by the automatic system.
footnotes
-
I want to remark the meaning of learning since it is commonly associated with pattern matching in machine learning tasks. Learning could be defined as a meta-function that lays - in hierarchy of cognitive function of human’s mind - above perception, memory, thinking, acting. The learning process encodes (transforms) in organized mental representation in connection with other known concepts. ↩
-
“Becoming a data-aware organisation means being able to see data opportunities and risks and translate them to actions. For that, you need an organisation that looks at projects from the data point of view and a few data specialists (depending on the size of your team) who can put that perspective into practice.” - source ↩
-
prototype theory is a theory of categorization in cognitive science, particularly in psychology and cognitive linguistics, in which there is a graded degree of belonging to a conceptual category, and some members are more central than others. - source ↩
-
Vernon, David. Artificial cognitive systems: A primer. MIT Press, 2014. ↩ ↩2
-
https://en.wikipedia.org/wiki/Theory-theory ↩
-
Cognitive psychology uses different and more glamoured terms, I mention them since there is an intersection of different discipline and it is extremely interesting to notice that. For that respect, ontogeny match with the definition of development, to not confuse with phylogeny which refers to the change of agent’s specie through evolution. ↩
-
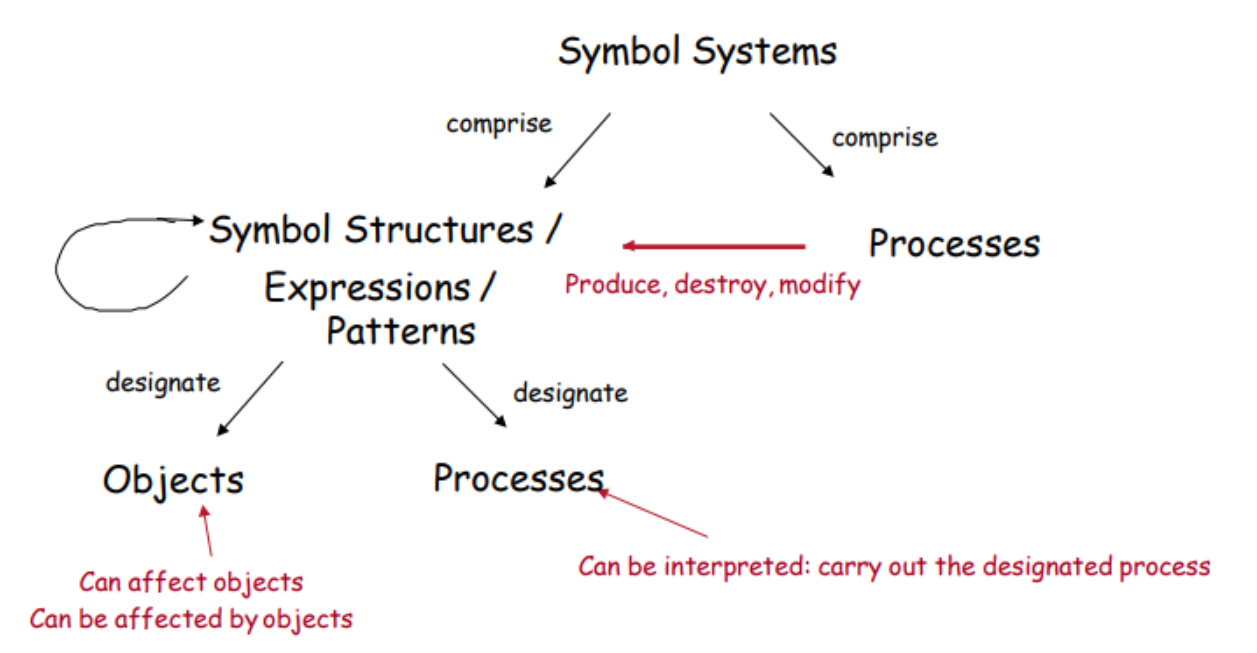
Like in the “physical symbol systems” (Newell and Simon 1975)
 ↩
↩ -
The idea “form follows function” was given by the architect Louis Sullivan. ↩