Consumer Problem Discovery and Solution Recommender with Knowledge Graphs
| Id | Status | Submission Date | Grant Date | Authorship |
|---|---|---|---|---|
| EP4181030B1 | Granted | 09 Dec 2021 | 24 Jul 2025 | 100% |
While browsing e-commerce stores in search of suitable items to purchase, consumers consider miriads of factors regarding the objective quality of the product offered by the website (price and features) and subjective characteristics like the social value (how the product is valued by others) and emotional value. Not only influenced by the single product, online consumers also evaluate the trustiness of the e-store in delivering what they promise for avoiding delays, missing consignments or anything related to bad customer service. Some factors are consciously scrutinized and other are driven by sub-conscious mechanisms that are that might be in various degree predicted. There are statistical mechanisms employed to predict whether the user is likely to abandon the purchase process (churn) based on tracked behaviors, but they lack the mechanisms to:
- understand the reasons why users don’t finalize the purchase
- apply any countermeasure to bring the user’s interest back
The method described here is intended to provide those capabilities with the least amount of effort by leveraging pre-processed information in the form of knowledge graph (KG) that is leveraged to detect objective and subjective consumers’ issues that might be caused by purchasing a product.
The proposed system is intended to make use of generic semantic knowledge in the form of graph of concepts in order to solve business problems. The rule engine is an extremely flexible information processor that elaborates the data present in the KG repository. The engine performs query, transformations, and constructs new knowledge based on the given set of rules. The input and output of this engine are concepts and relations among them that are computationally manageable for obtain a proper result. The result could be a hypothesis on particular preferences of the user, a product recommendation, or anything that might be occur as wishes of the functional designer. The engine offers the following capabilities:
- Abstract the underlying KG database in a concise, simple way
- Defines a set of existential rules based on logic programming
- Generalizes a limited set of domain specific rules that can be applied to wide range of cases/items
- Run the rules recursively and create new knowledge
The engine’s output is then rendered in the UI displayed as interactions. The Ecommerce storefront is the source of the engine’s input in terms of user-based events (clicks, changes on item’s color/variant, etc.)
knowledge graph
It is a graph database in form of triples: subject → relation → object. It could be stored in several formats (RDF, OWL) or could be served by graph database engines (Neo4j, GraphDB etc.). When it is just provided as file, the engine loads the content in memory structures ready to be elaborated. If the KG is backed by a graph database, the engine will have to use the specific DB driver in order to perform queries and/or store new data. The source of KG could be one or a mix of those options:
- Open source (ConceptNet, DBPedia, WikiData)
- Commercially licensed (Diffbot)
- Self-extracted from raw corpora (specific for industrial/legal domains)
Datalog
The data is queried and constructed in the Rule Service by a domain specific language, which is inspired by Datalog, a simple graph-oriented representation language, used also in logic-oriented system such as Prolog and Answer Set Programming (ASP). Datalog could be stored as a graph in the graph DB, or it could be stored just in files by using the DSL described in this document. In Datalog the triple is represented as records in the format relation:subject:object. The underlying in-memory encoding allows efficient predicate resolution through direct access data structures. For example, if we want to express that the concept “mammal” extends the concept of “animal” we simply define: isA:mammal:animal. The rules are expressed in form of consequent ← antecedent, whereas the antecedent is matched, the consequent will be constructed, otherwise the rule does not apply. In Datalog the concepts can be substituted by variables. In the example below, the grandfather is the father of the father:
(grandfather:X:Y) :- (father:X:Z, father:Z:Y)
Datalog abstract the underlying KG storage and provide a boilerplate-free language for KG and rules representation. It is implemented with the following algorithm.
Suppose we have the underlying DB: father:Ilario:Giancarlo,father:Andrea:Ilario
- All arguments in the antecedent are fetched against the DB.
a. Elements in the argument that are strings, are used as discriminator e.g., fetch all triples with first element equals to “father”
b. Element with variables instead is associated with the value retrieved in the DB - In the joining phase, elements with common variables are combined together, the others are removed. E.g., after this process we have a table with 3 variables as header: X,Y,Z, and one single row: Andrea,Ilario,Giancarlo
- In the consequent element, the table above is used to construct the new elements, through variable substitution. E.g.,
grandfather(Andrea,Giancarlo)
Relation data-types
The generalist type of KG like ConceptNet, define a set of relations to capture common and informative patterns. In the prototype I made, I’m adopting the following relations:
antonym: opposite meaning e.g., antonym:black:whitesynonymisA: the subject extends the object e.g., isA:human:animalhasProperty: the subject has the property indicated as objectcauses: the subject is a direct cause of the objectdesires: the subject desires the objectpartOf: the subject is a part of the objectimplies: the subject is correlated with the objectrequires: the object is required by the subject
Semantic algebra
Those relations are created by the Knowledge Rectifier only once for the Domain KG. Nevertheless, this process is also executed for the relations created by the Rule Service during its processing.
prevents
prevents(X,Y) :- causes(Z,Y), antonym(X,Z)
prevents(X,Y) :- antonym(Z,Y), causes(X,Z)
e.g.: if the “lack of study” causes “ignorance” and “learning” is the opposite of “lack of study”, then “learning” prevents “ignorance”.
implies
implies(S,S2) :- causes(Z,S), causes(Z,S2), S!=S2
implies(S,S2) :- implies(S,Z), requires(Z,S2), S!=S2
The “implies” refers to concepts that might be correlated, that means if A causes B and C, B implies C (and vice versa). It is a relation that mildly co-relates two or more concepts.
Inheritance from “isA”
X(S,Z):- isA(S,S1), X(S1,Z), S!=S1, not(antonym(Y,Z), X(S,Y)
All Properties of a concepts are inherited by its extensions. E.g., birds can fly, then all eagles can fly. Since this principle is not always true, it is assured that if the extension (for example the penguin) has a property which is opposite to its parent, then that property won’t be propagated to that instance. E.g., the penguin has the property “stay on the ground” which is antonym to “can fly”, this rule can’t propagate the bird’s property “can fly” to the penguin.
Replicate relations with their synonyms
X(Y,Z) :- X(W,Z), synonym(W,Y)
If A has a property B, and B is synonym with C, A has a property with C as well.
relatedTo
relatedTo(Y,X) :- hasProperty(X,Y)
relatedTo(S1,S):- relatedTo(S,Z), hasProperty(S1,Z), S != S1
It’s a weak relation that generalizes that hasProperty relation in a recursive way.
Transitive
if A is a B, and B is a C, then A is a C. Affected relations:
transitive(isA, causes, requires)
A(X,Y) :- transitive(A), A(X,Z), A(Z,Y)
Synonym
Elements related throughout the synonym relation share the same relations.
X(Y,Z) :- X(W,Z), synonym(W,Y)
X(Y,Z) :- X(Y,W), synonym(W,Z)
RULE SERVICE OVERVIEW
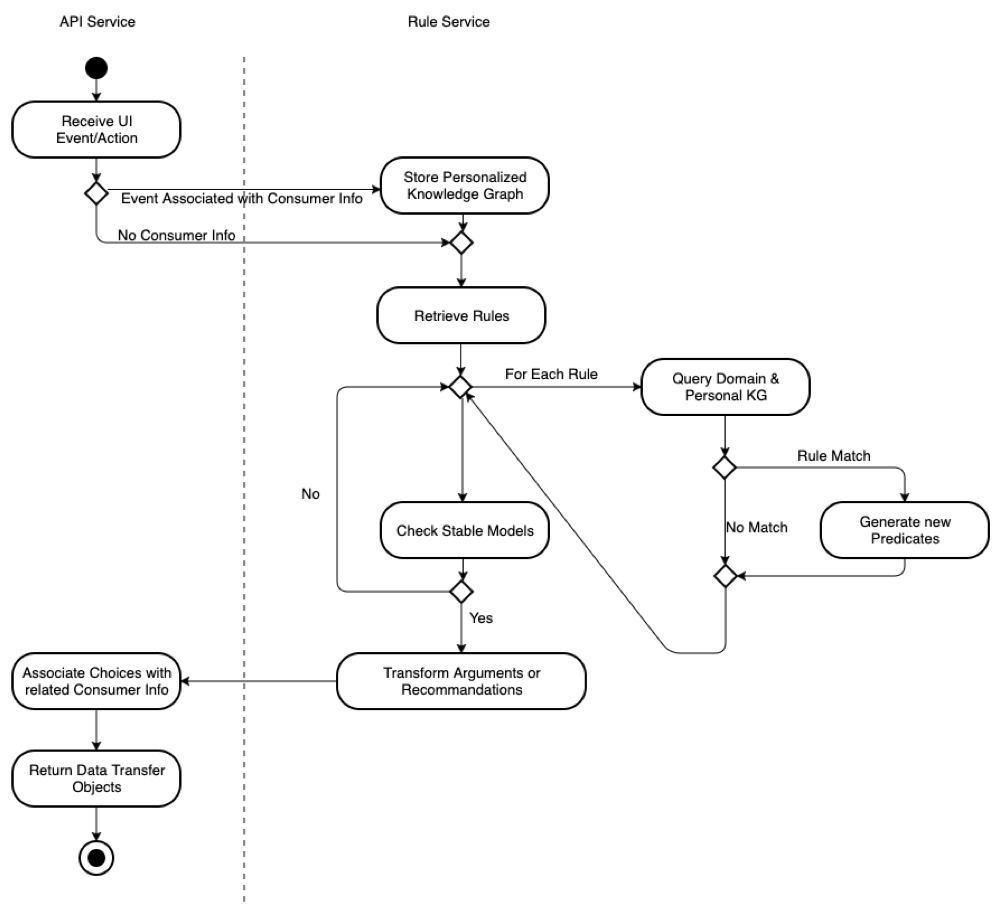
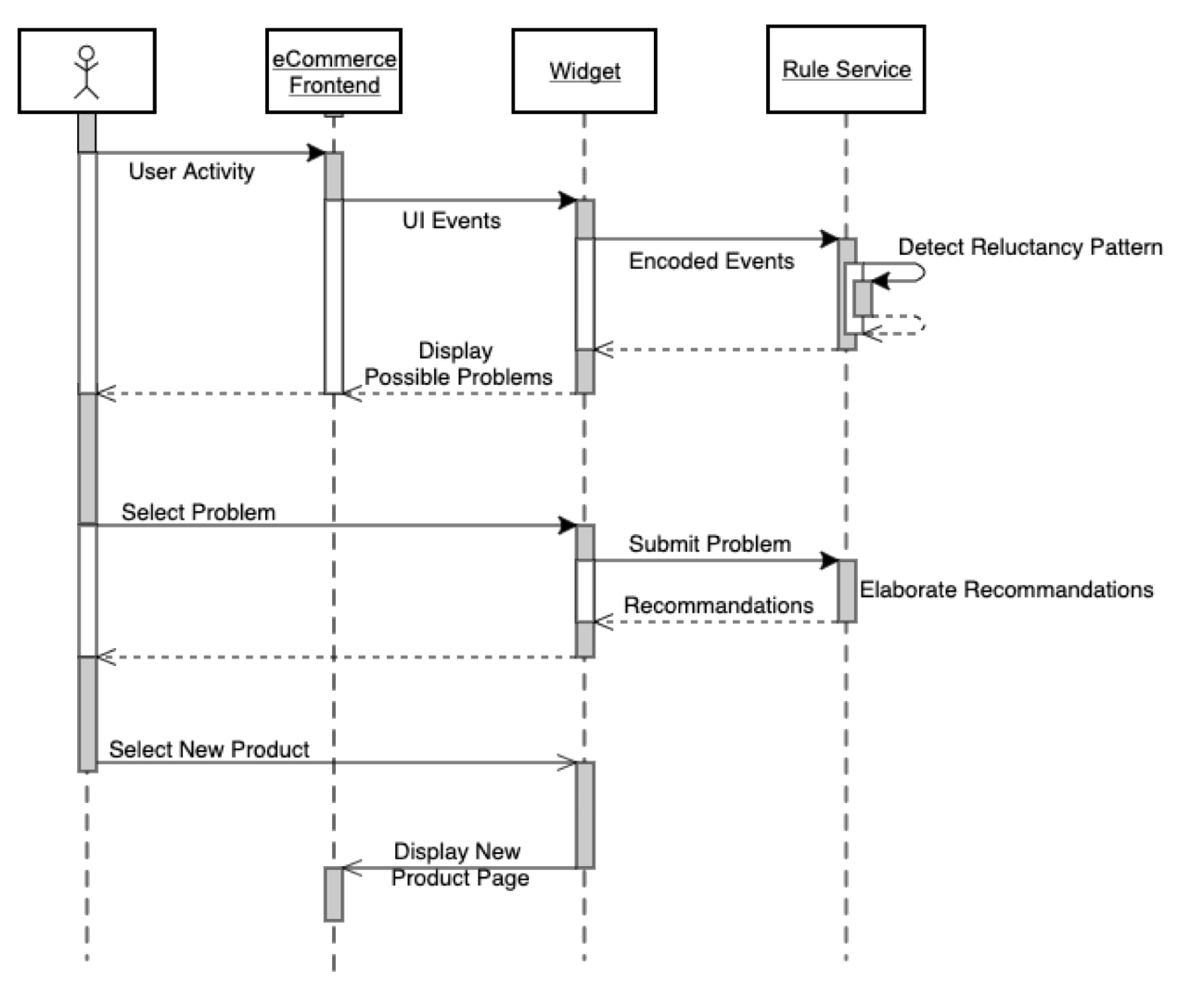
When the frontend will trigger events (user click image, select variant, add to the cart…) or when the user clicks an element prompted by the Widget, a request is made to the API Server which forward the request to the Rule Service. It stores the info related to the user’s action (if any) and then merge the information with the KGs (domain KG, personalized KG and Labelled catalog). The total set of facts is submitted to all rules configured into the system, and if activated they will generate new facts that are added to the whole of facts already present, recursively. The process stops when stable models are reached, that means, the system stops to iterate through the rules when there are no new facts generated from the previous iteration.
CATALOG LABELLING
The system is intended to be integrated with the merchant’s catalog. Moreover, it is expected that items in the catalog are enriched with triples compatible with the relations listed above. This enrichment is processed by the Product Tagger. Let’s consider some items such as:
- Canon EOS-1D Mark II
- isA: body camera
- hasProperty: DSLR
- Canon PowerShot G5
- isA, compact camera
- Online Course Canon
- isA: online course
- Canon RF 100-500mm F4.5-7.1
- isA: zoom lens
- hasProperty: telephoto focal
- Canon 50mm
- isA: prime lens
- hasProperty: standard focal
BUSINESS CASE: DETECT CONSUMER RELUCTANCY WITH AN ITEM
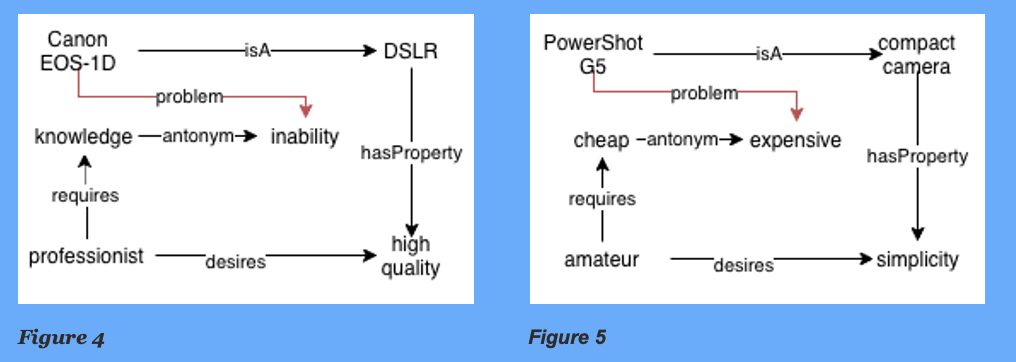
When the online consumer opens an item page but lingers upon it or leaps over the buy button or somehow trigger an alarm detected by third-part services indicating the user is interested on that item but won’t proceed with the checkout, the system can search for motivations of such reluctancy. Let’s assume the user is looking to a Canon EOS-1D (which trigger the fact: details:EOS-1D) and also the so called “reluctancy” event has been triggered (fact context:reluctancy). considering we have the following KG:
Then the rule below will be activated, and it will generate the problem for that product.
problem(X,P):- context(reluctancy), details(X), relatedTo(X,S), desires(S1,S), requires(S1,S2), antonym(S2,P)
Taking the example if Fig.4, it queries the KG by searching what is the opposite (inability) of the required concept (learning) desired by “professionist” that is related to the visited item (EOS-1D). This rule is generic and might be applied also for different products (Fig.5).
In the case of reluctancy on watching the “Canon EOS-1D” the system might convert this information into a question to the user by mapping information problem:inability into a web window with title “Any Concern about this product?” and then a button referring to that specific problem with text” How to use it?”. If there are more problems within the product, they are listed under the same title.
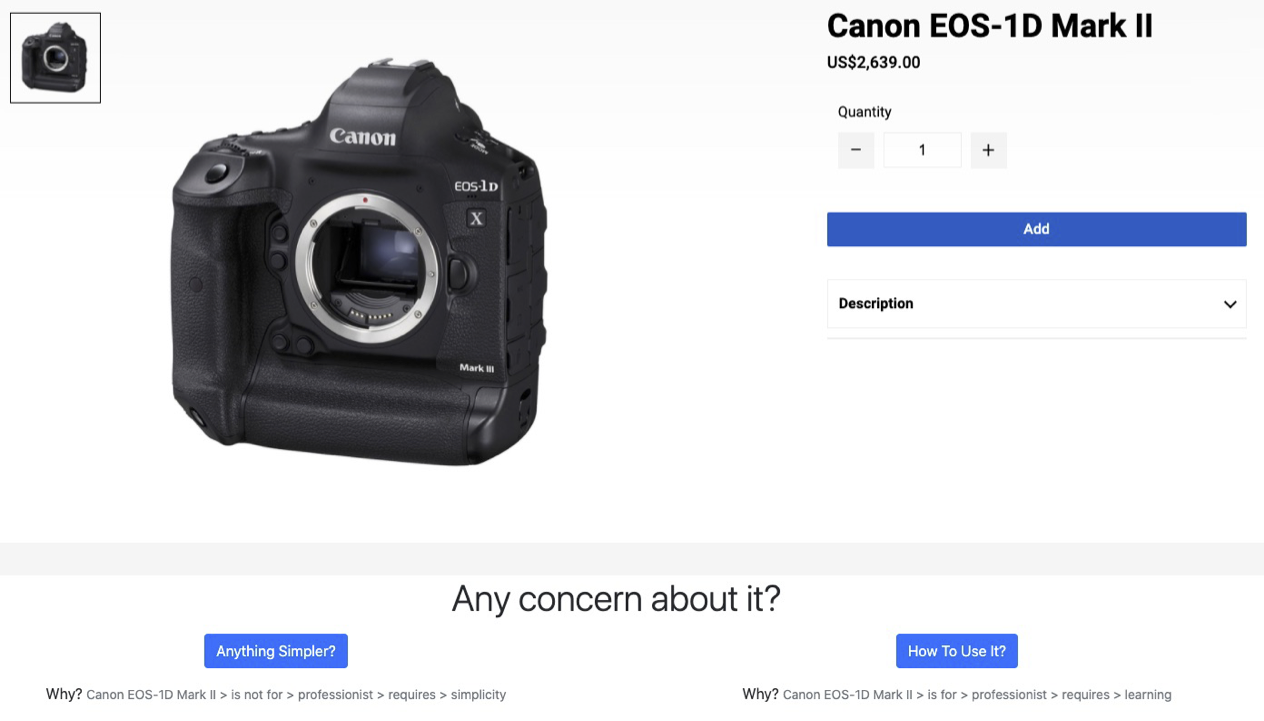
If the user clicks on “How to use it?” the information problem(inability) is stored in the session and if the user is registered is stored in the persistent Personalized Knowledge Graph, which is a database of facts related to the user and used in subsequent elaborations.
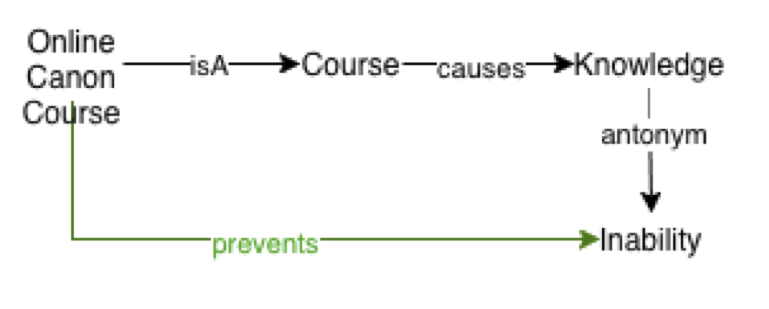
The solution of a problem is something that prevents that problem. By running the existential and extended rules over a KG that contains the relations above (see inferred relations), the new relation prevents is created between the Online Course and the problem, and that product should be recommended to the user.
recommend(X) :- problem(Y), prevents(X,Y)
The recommendation (the course) is visualized as the solution for the inability problem and if the user clicks it, the main browser window page will be directed to that product details page.
Claim
The main contributions are
- Usage general available common-sense knowledge in order to solve business problems.
- Combination of Datalog as data interface point within Domain KG, Personalized KG and Catalog in eCommerce.
- Algorithm of recursive elaboration of simple rules for logical inference into new useful relations.
- Portable interface (Widget) with existing eCommerce solutions (Upscale) or integrable by mean of loading a JavaScript on custom pages, as a point of interaction with the consumer.