Deeplearning in Text Classification
In the Divine Comedy, Minos is a daemon appointed to guard the entrance of the hell. He listens to the sins of souls
and indicates them their destinations by wrapping his tail as many times as the assigned circle.
The figure is emblematic of the machine learning classification, where an entity is identified as belonging to
a category or to another. Rather than condemning souls to endless pains, the harmless tool I am describing can judge whether an user’s utterance belongs to a specific intention, or to a limited range of emotions. Namely, it can serve intention recognition and sentimental analysis.
In the realm of conversational commerce, the examined sentence could be:
I want to buy some apples and pears
The system recognizes the intention search and presents the results.
Intention prediction is not an untackled problem and the market offers plenty of services.
There are many players such as Google (Api.ai), Facebook (Wit.ai), Microsoft (Luis.ai) just for mentioning some of them,
but this shouldn’t prevent further explorations in the topic, sometimes with unexpected positive surprises, as shows in the graph.
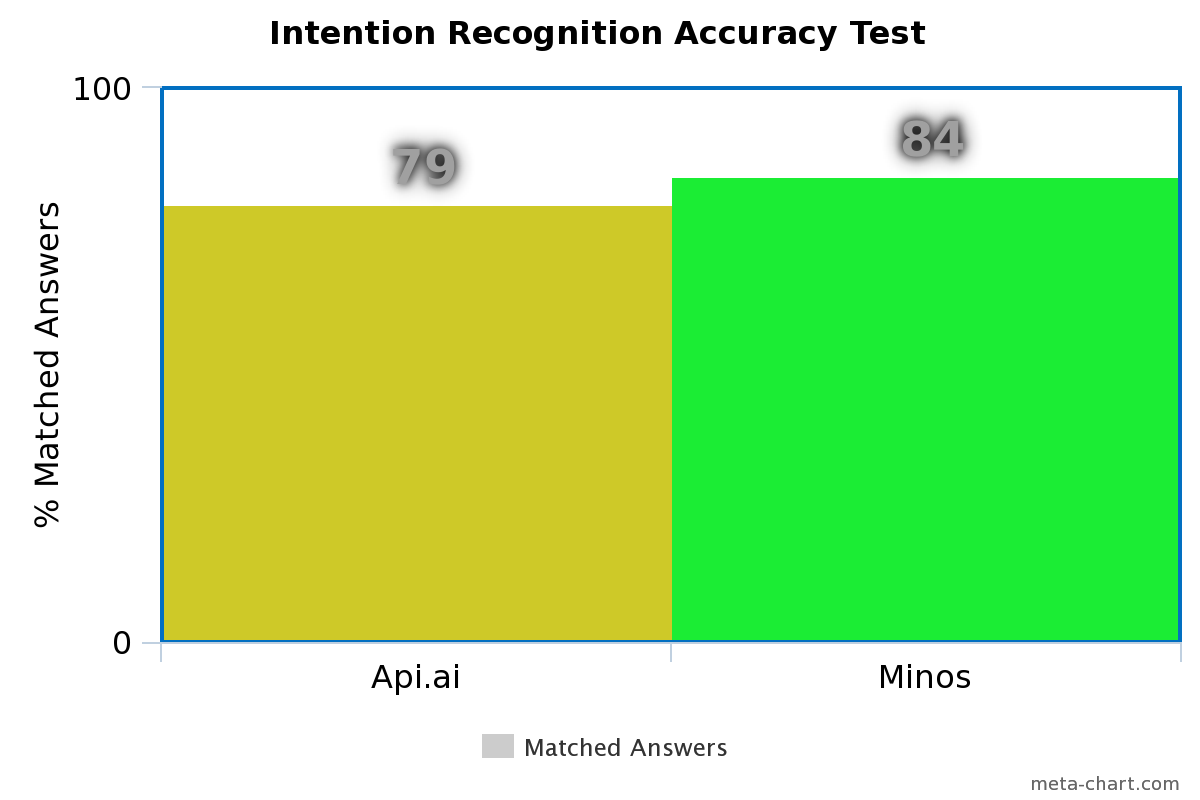
The test was performed against real data used for training the deployed model of the Chatbot system and the results are relevant for the real working scenario, so no cherry picking in this case. 300 training samples, 56 test samples for 25 classes, these are the dataset’s numbers.
Minos, the text classifier, uses an ensemble of machine learning models. It combines multiple classifiers for getting a good prediction out of utterances submitted to Charly.
One of the models is based on Convolutional Neural Networks (CNN).
CNN in NLP
CNN is mostly applied to image recognition thanks to the tollerance on translations
(rotations, distortions) and the compositionality principle (entities are composed by its constituents).
Admittedly, CNN might appear counter-intuitive at a first approach because text looks very different from images:
- The order of the words in text is not as important as the order of the pixel in an image.
- Humans percept text sequentially, not in convolutions.
Invariance
Entities like images and texts, should be compared differently. The smallest atomic element in text is the single charater, rather than the word, like the pixel in images. The proportion is more like:
text : char = image : pixel
By this angle of view, the order of characters in sentences is fundamental. Convolutions in text come in form of:
single word => bi-grams (two adjacent words) => n-grams
like graphical features
lines , corners => mouths, eyes => faces
come out of portraits.
In CNN the pair adjective + object for example,
could be recognized invariantly of its position, at the begin or at the end of a sentence, exactly like a face is recognized wherever it is located in the whole picture.
Sequentiality
It might seem more intuitive to apply Recurrent Neural Networks (like LSTM, Attention or Seq2seq) for text classification,
due to the sequential nature of RNNs algorithms. I didn’t run any test on them so far, but I would promptly play with TreeLSTM. CNN performs well, and one might say that Essentially, all models are wrong, but some are useful, an essay the fit with the idea that final outcome drives the decisions, and experimental results play an important role.
Word Embeddings
Alike any NLP, in CNN words are replaced by their correspective semantic vector. Most famous are Google word2vec, GloVe and FastText.
I decided to make use of ConceptNet Numberbatch
that took first place in both subtasks at SemEval 2017 task 2.
Moreover, the vector file is very small (~250M) compared to Google News word2vec (~1.5G) and from an engeneering point of view, those numbers matter.
Minos is still experimental and not well tuned, doors are open for improvements. An aspect shouldn’t be ignored on working with CNN is the Catastrofic Forgetting, an annoying phenomenon that ruins irrevocably the entire training.
Comments